Pipeline
To help Mozart Data users view the data sources of the transform models, we have built the Pipeline feature. Here some high-level benefits of the Pipeline feature:
-
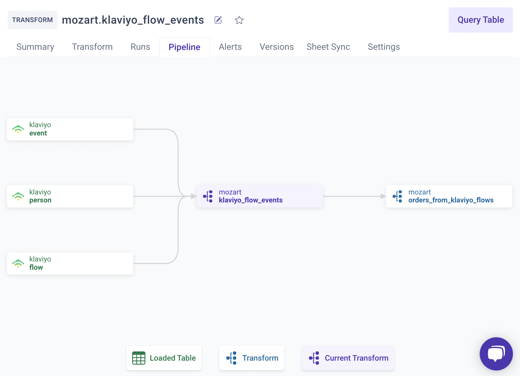
Mozart’s Pipeline feature infers and visualizes the data lineage automatically based on the upstream data sources flowing into your transforms and the downstream transforms that are dependent on the result of the current data / transform
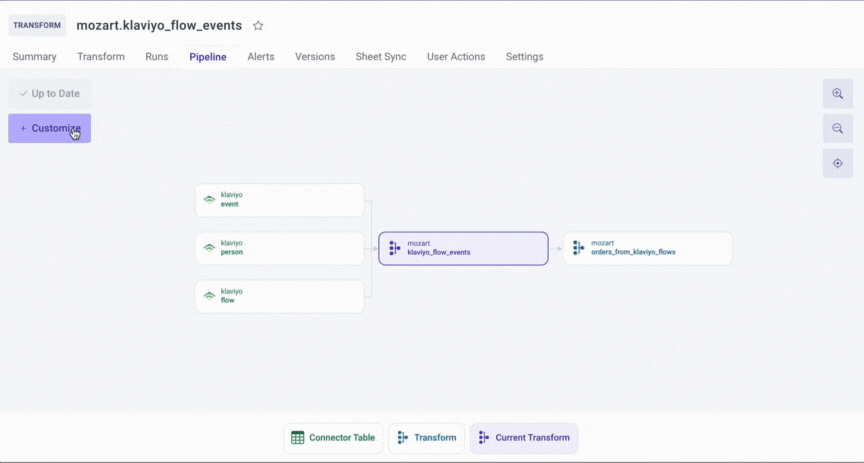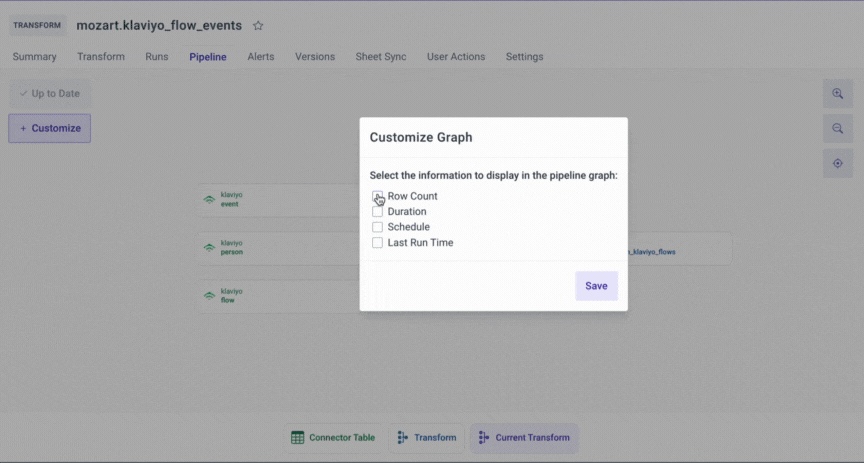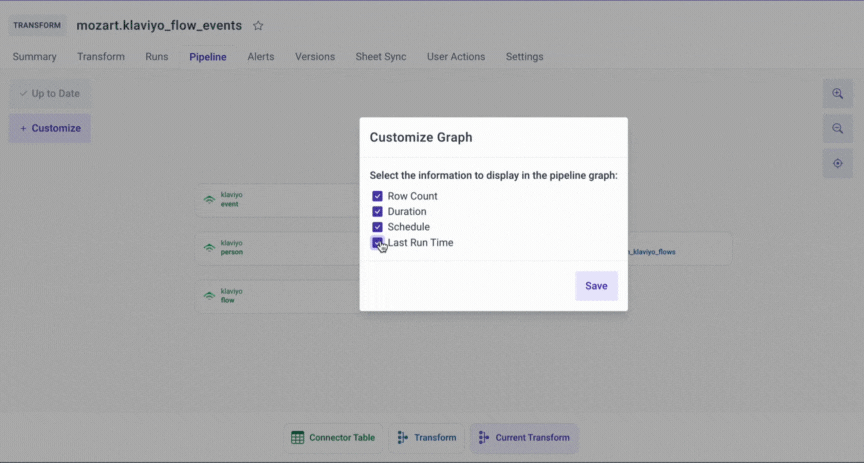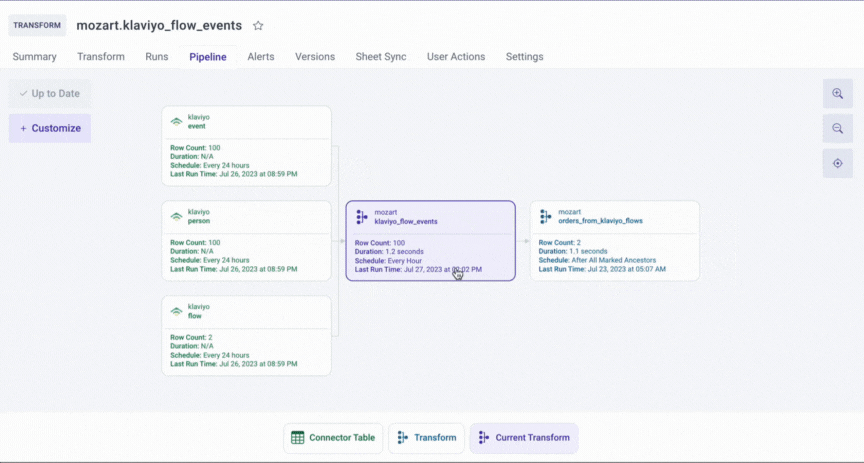
- You can choose and display important information about the tables in the pipeline graph, such as row counts, last run duration, last run time, and the run schedule
-
You now have more control over scheduling the transforms based on the status of upstream dependencies (“Ancestors”) rather than relying on the set interval, which can be accessed in the Transform tab
Upstream Dependencies & Downstream Dependencies
- To the left of the current transform (mozart.klaviyo_flow_events) are the upstream dependencies (klaviyo.event, klaviyo.person, and klaviyo.flow)
- The downstream transforms now appear to the right of the current transform, indicating all of the models that are reliant on the results of mozart.orders_from_klaviyo_flows
Schedule transforms based on Ancestors
We now offer more control over the freshness of your data. You can schedule the transform run after all marked ancestor models have refreshed, or at a specific time or cadence.
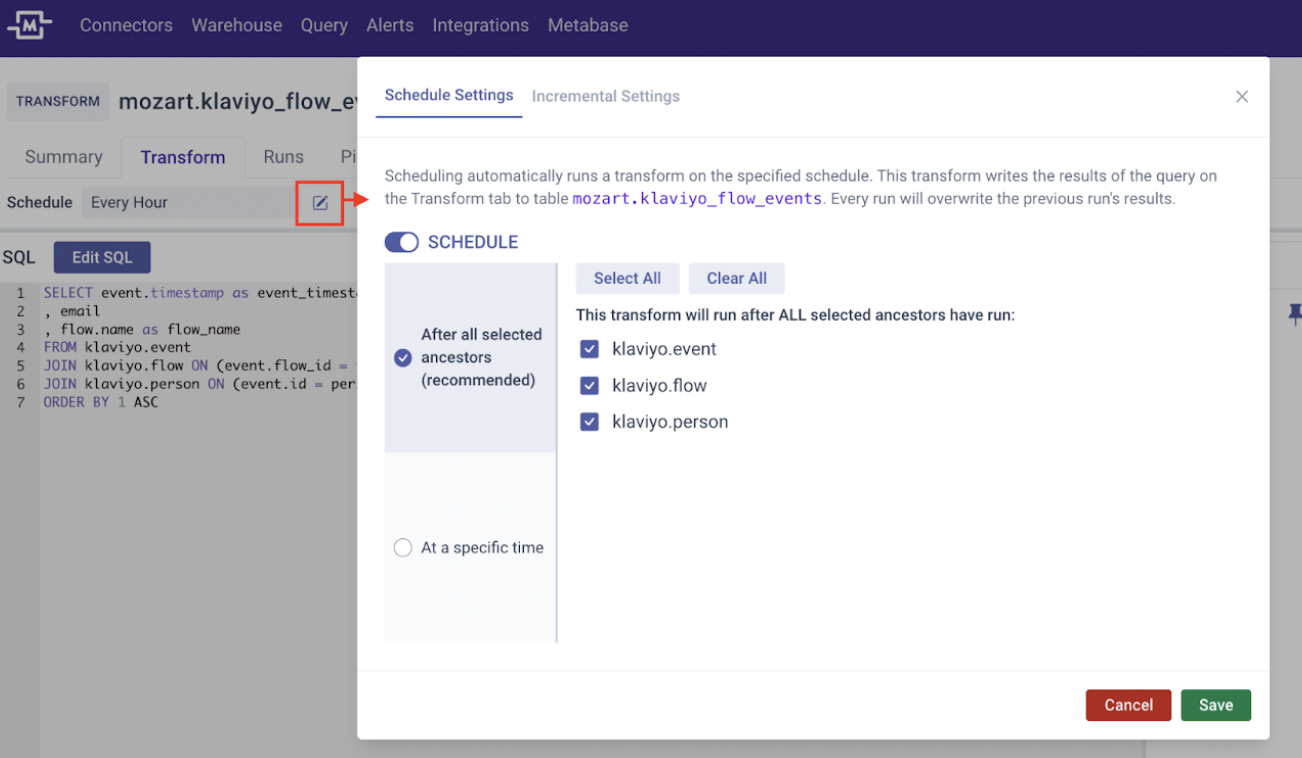
1. After All Marked Ancestors:
Set the transform to run only after the marked “ancestors” (upstream dependencies / data sources) are run. This ensures the data is fresh at every level of its upstream models. Select as many ancestors you want.
2. At Specific Time:
Set the transform to run at a specific time or intervals using Cron.
Examples of New Pipeline Configuration: mozart.klaviyo_flow_events
- klaviyo.event, which refreshes daily at 9 a.m.
- klaviyo.flow, which refreshes daily at 10 a.m.
- klaviyo.person, which refreshes daily at 11 a.m.
Scenario 1. You select After All Marked Ancestors and mark all three ancestors.
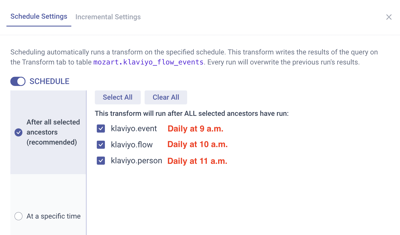
Result: The transformation model mozart.klaviyo_flow_events will be refreshed at about 11:02 a.m., slightly after the last upstream dependency table (klaviyo.person) has refreshed.
Best For: When you are concerned about the freshness and completeness of the data over speed.
Scenario 2. You select “After All Marked Ancestors” and mark klaviyo.flow only.
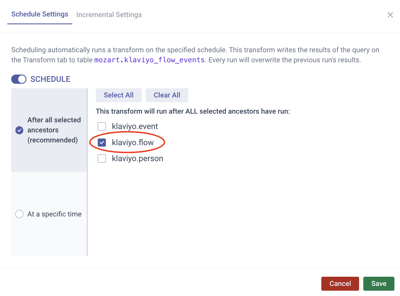
Result: The transformation model mozart.klaviyo_flow_events will be refreshed at about 10:02 a.m., slightly after the last marked upstream dependency table (klaviyo.flow) has refreshed.
Best For: When you are most concerned about the data freshness from a specific table(s).
Key Benefits of Pipeline
- Visibility. Pipeline graph visualizes both the upstream and downstream dependencies of your data so you can quickly understand how the transform is built and identify root causes when there are data integrity issues.
- Freshness. Ensure the freshness of your data by defining the trigger for refreshing. These settings provide more fine-tuned control than having a set schedule. With a schedule, there may be instances when data is updating frequently but you are waiting hours for the transform table to reflect those changes.
- Cost-efficient. Bring data warehouse compute costs under control by avoiding unnecessary runs when the upstream tables have not refreshed yet. There may be other times when you're unnecessarily running a transform and wasting compute. Update the table based on its dependencies to reduce data latency in some cases and conserve Snowflake compute credits.