General
How do I sign up for Mozart Data?
What is Mozart Data?
Mozart is the easiest way for teams to automate data collection and transform it into actionable insights. Mozart manages your data pipeline and runs your data warehouse. We take this tedious work off your data engineer's desk, so they can focus on what you hired them for.
What is a Modern Data Stack?
What data sources do you support?
Mozart connects to over 150 data sources out of the box.
See the full list.
What do I do if I need a data source connection that you don't support?
Contact support@mozartdata.com, because we may have experience or resources to deal with your specific issue. Worst case scenario, we can work with you to create a custom data connector.
How does Mozart handle data security?
How do I get support?
We assign every new customer a dedicated analyst and support engineer when they sign up with us. If your team is using Slack, @mention one of these people in your company's shared slack channel and we'd be happy to help. You can also email support@mozartdata.com
What are Fivetran and Snowflake? How are they related to Mozart Data?
Fivetran is a service Mozart Data uses to copy data into our data warehouse. Mozart uses Snowflake as its data warehouse. Snowflake is a particularly good choice of database for doing analytics.
Why is Snowflake a good Data Warehouse?
Snowflake is both the highest-performing and the most cost-effective data warehousing solution in the marketplace today. It has become the de facto market leader by shattering the old paradigm of coupled storage and compute resource allocation, which would often times lead to costly and inflexible data infrastructure that required dedicated maintenance and optimization operations and unnecessary provisioning of additional storage or compute to satisfy the necessity of the other, while still presenting the risk of untimely data consumption bottlenecks and failures. Not only does Snowflake tailor your spend to your needs, it also helps you reduce latency and cost by applying sophisticated performance optimizations such as self-organizing storage and new compute scaling, bursting and caching capabilities, features that make accessing your data products faster and more reliable through the traditional pain points of explosive growth spurts on the input or output side of your data stack.
Read more on our blog
Data Warehouse & SQL
How do I access my data?
- Log into (https://app.mozartdata.com/)
- Go to (https://app.mozartdata.com/integrations)
Where can I find a good SQL Tutorial?
Mode has a good one. Coincidentally, they are a great BI Tool.
What flavor of SQL do you support?
Why are certain SQL functions not working in Mozart?
The SQL we use is SQL through Snowflake. Though much of it is identical to the SQL you would use for MySQL or other databases, for a full list of available functions and syntax, see Snowflake’s SQL Function documentation
How can I parse JSON in Snowflake?
Here are some useful docs on parsing JSON in Snowflake.
How do I add a User Defined Function (UDF) to Snowflake?
How do I write data directly to Mozart's warehouse with a tool like Retool or a custom program I wrote myself?
Before you begin, make sure that:
- You don't want to edit data that Mozart is already syncing with a connector. If this is the case, write to the data source that Mozart is syncing so that you have one source of truth.
- If your program already knows how to write to a CSV file, a database, or any other data source a connector can sync to Mozart it might be easier to write to that source and then use a connector to import that source into Mozart than to modify your program to write to Mozart directly.
I still want to write directly to Mozart's warehouse:
When you create your account Mozart creates a user with read and write access to your data warehouse. You can use this user to log in any tool that can write to a Snowflake database. Go to the integrations page for examples and login credentials.
Warning:
If you decided to write data to Mozart directly, create a new table inside of a new schema. Schemas and tables that are owned by a connectors or transforms will have the table's contents rewritten every hour by Mozart's automated processes and your writes will get lost.
Snowflake
What is a Snowflake Reader account and how many do I get?
Reader accounts (formerly known as “read-only accounts”) provide a quick, easy, and cost-effective way to share data without requiring the consumer to become a Snowflake customer.
You start with 20 accounts (includes inactive accounts), but you may request more from Snowflake.
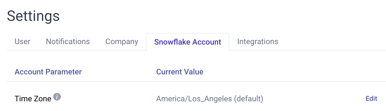
How do I change the default timezone?
In the Settings → Snowflake Account tab, you will see the option to select your default timezone
What are some options of how to get data into Snowflake?
- Fivetran existing connector
- Portable existing connector
- Portable new connector
- Fivetran new connector (2-3 months all-told if they do it most likely)
- Could see if Stitch or Airbyte or other vendor has a connector
- See if the source has any automated data export, say to s3 or google cloud storage or SFTP or email. If so, and the data is sufficient, use that with a Fivetran connector from wherever they're exporting to.
- Manually build it themselves, I'd recommend Fivetran custom connectors framework, so Fivetran still does half the work: https://fivetran.com/docs/functions
Fivetran
How can I add users into my Fivetran account?
As long as you are an admin on the account, you can log into your Fivetran account, click on the destination tab on the left, then go to the users tabs and add a user. For further instructions, see the Fivetran documentation.
Pricing and Usage
Why is my usage so high?
To understand usage, check out this document we wrote: Understanding Usage
To initially limit your usage, we recommend checking your settings, and if you still have questions, let’s set up a call
What are the best tips for saving costs while using Mozart?
Check out these two pages we made to help you save costs:
Data Integrity
I’m still seeing data that I deleted in my data source. What do I do?
Something to know is that Fivetran never deletes any rows.
If a row is deleted in the source table, Fivetran generates a new column _fivetran_deleted and sets the value to ‘true’ for that row. Deleted rows don’t count towards MAR, but if you want them to be deleted, you can turn on the ‘Auto-Delete _fivetran_deleted Rows’ function on the Mozart - User Setting page.
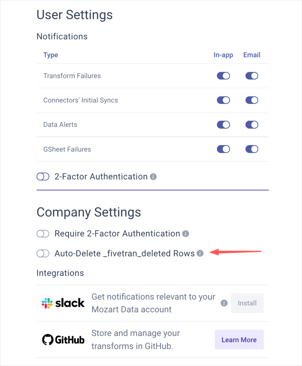
How do I get notifications for different pipeline issues in my email, or within Slack?
You can get notifications for data alerts in 3 different ways — in-app, email, and in Slack (through our Slack integration). Go to the Notifications tab in the Settings page, and you’ll be able to choose how you get notifications for a handful of different things, including data alerts.
Miscellaneous
Does my data in the google sheets connector need to be hard coded or can it still contain formulas?
It can contain formulas that both reference other cells within the same sheet or cells within other sheets - regardless of if the referenced cells are a part of the selected named ranges.