Disclaimers:
- The whole point of Mozart Data is to make better business decisions, faster, with fewer people. You should optimize for that, not saving on usage. Saving a few dollars on server bills would be penny wise and pound foolish if it cost your staff more man hours or caused your company to make a bad decision. In summary, cloud computing is many orders of magnitude cheaper than payroll or missed business opportunities.
- Unless you have millions of rows the techniques outlined in the document are unlikely to save you appreciable money.
- It is recommended that you start by applying these techniques to your top five biggest tables. Those tables are usually huge outliers and fixing the top five is probably good enough.
- Read How do I understand my usage before reading this page.
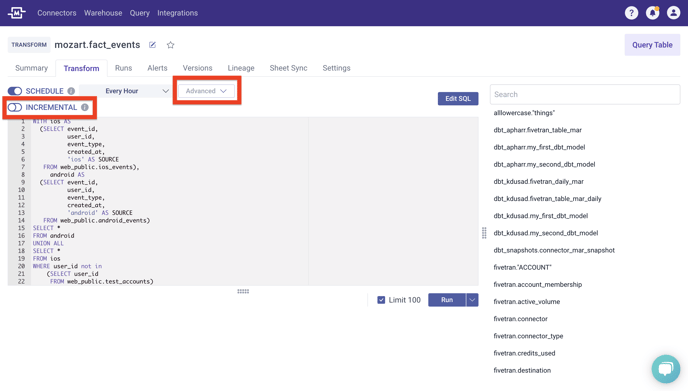
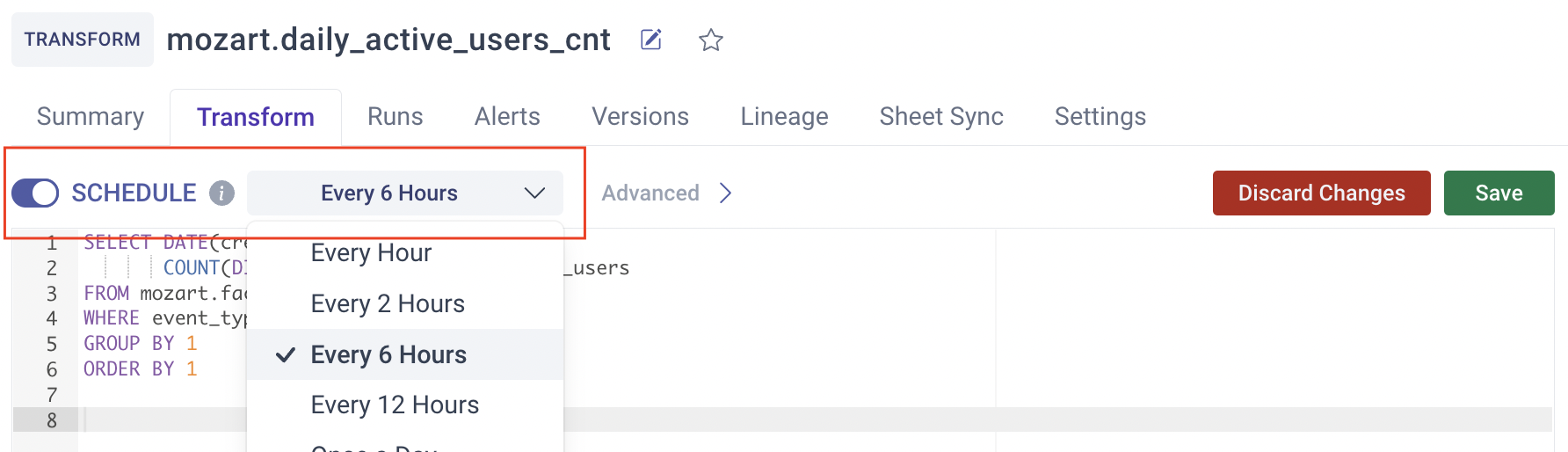
Schedule Transform Runs Less Often
Difficulty = Easy
You can schedule transforms to run only as often as you need them to be up to date, say once a day. This will save on compute usage. We recommend you set your transforms to run frequently unless your compute bill is large. It is probably more costly to accidentally make a bad decision because you didn't realize your data is a few days old than to run your transforms more frequently. Protip: You can set transforms to run right before you weekly meeting with custom transform scheduling.
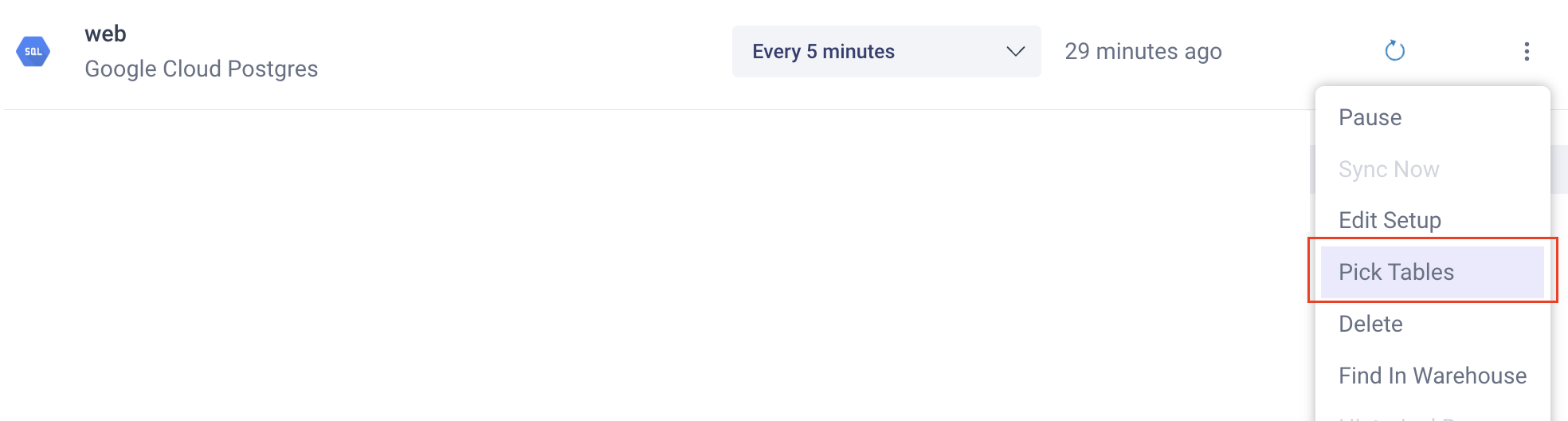
Set Connectors to only sync the data you need.
Difficulty = Medium
On Salesforce and database connectors you can set your connector to only import the tables and columns you need. If you stop syncing an entire table that will definitely save MAR and storage. If you keep syncing a table but stop syncing columns that you do not need and that change when the values in the table you care about do not this may also save you MAR. We recommend syncing everything unless you are incurring a lot of costs and are very confident you won't need the data later. Your staff may not be able to answer a future question because they don't know a certain piece of data exists because your connector is not syncing it.
Protip: Contact Mozart Support for help finding data you don't use. We have a report we can run to identify unused data.
Sync Directly To Snowflake When Possible
Difficulty = Medium
A handful of data sources, notably Segment and Amplitude, can sync directly to Snowflake. This bypasses Fivetran connectors and will save MAR. Note, these datasources might not sync data in the exact same way a Fivetran connector does, so you might need to use a transform to reformat the data directly synced from a source to match the format of data that was previously synced with Fivetran. Segment only syncs data once an hour where as Fivetran can sync data every five minutes. So, this is not a good option if close to realtime data updates is important to you.
Extract commonly used SQL idioms
Difficulty = Medium
If several of your transforms have the same CTE or subquery pasted at the start of them, you could just put this shared idiom in it's own transform and query that transform's results in all your other transforms. This may save compute and employee time.
Rewrite slow queries
Difficulty = Hard
If you have a query that runs on a very large data set it may be possible to rewrite it in such a way that it runs quicker; thereby saving compute and employee time waiting for jobs to finish. If you aren't extremely proficient with SQL, contact our support staff and they can help you. This is probably only cost effective on transforms that take over ten minutes to run.
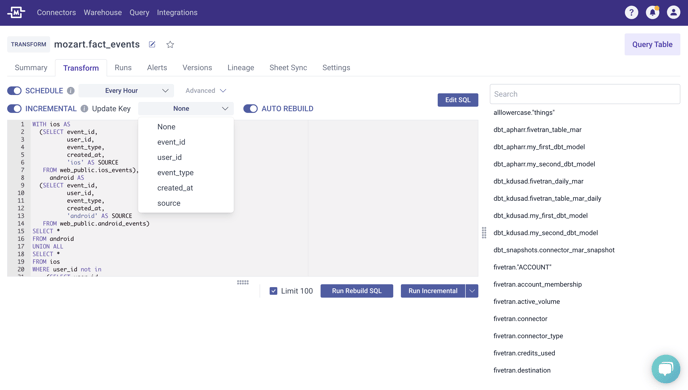
Incremental Transforms
Difficulty = Hard
If you have a transforms where new rows are appended on each transform run and existing rows are not updated on each transform run, Incremental Transforms can save on compute. We do not recommend them on small tables. It's not worth adding the extra complication unless your transform is running very slowly.