GitHub Integration
We recently launched GitHub integration to allow users to store their transform code in a GitHub repo and incorporate Pull Request (PR) workflows in an effort to the improve data quality management and version control process. Go to Using Mozart Data with GitHub to learn more.
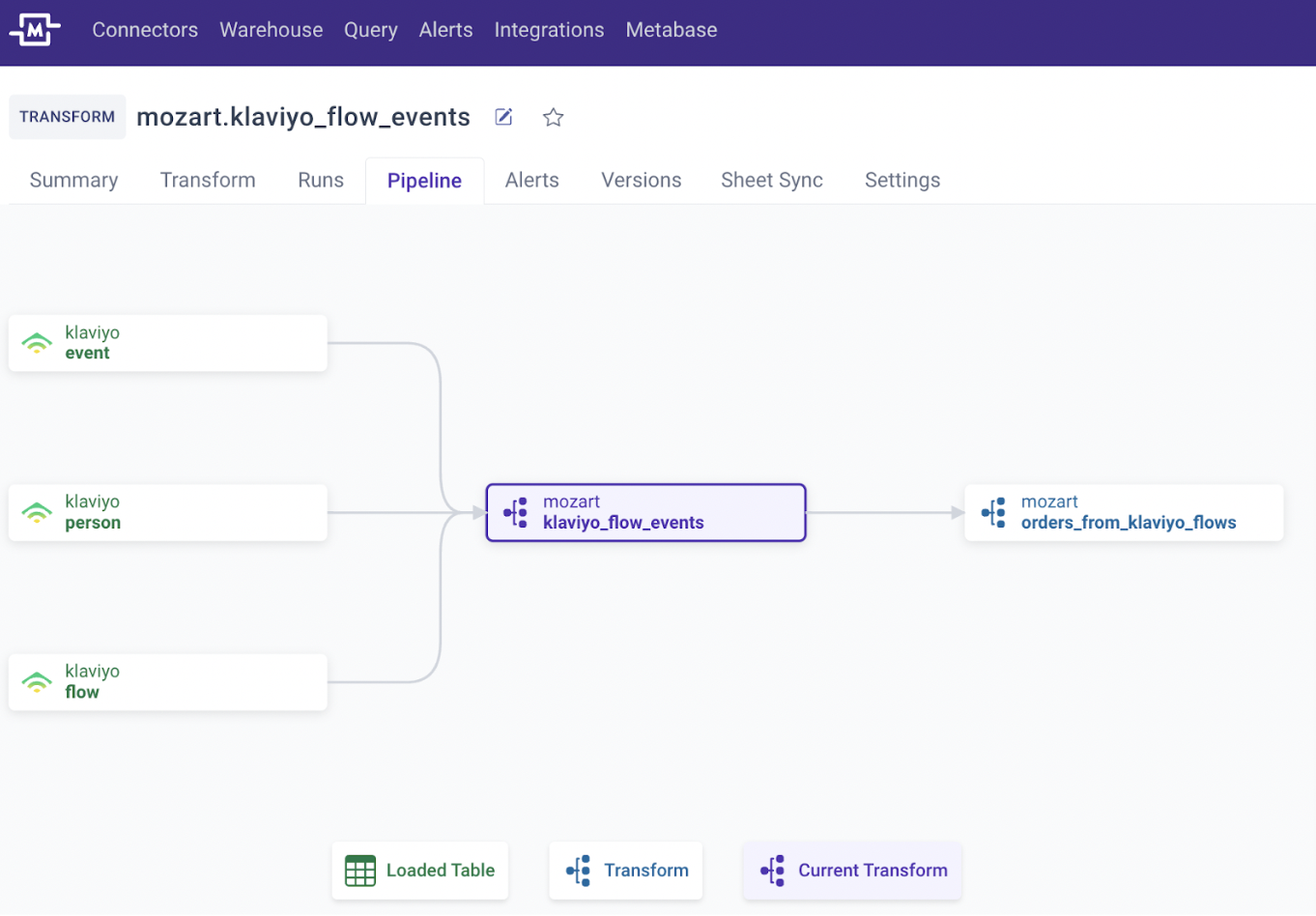
Pipeline Feature
We are excited to make enhancements to the Lineage tab, which showed the data sources and relationships of a transform model. The Lineage tab is now called "Pipeline" with two major changes:
-
Mozart’s Pipeline feature infers and visualizes the data lineage automatically based on the upstream data sources flowing into your transforms and the downstream transforms that are dependent on the result of the current dataset / transform
-
You now have more control over scheduling the transforms based on the status of upstream dependencies (“Ancestors”) rather than relying on the set interval, which can be accessed in the Transform tab
Go to the Pipeline Feature page to learn more about the feature and see examples.